How Websites Distinguish a Real User from a Bot

Many people still believe that websites detect bots using a simple rule: too many actions in a short period of time. Reduce the request frequency, and everything will work smoothly. In reality, this approach has long become outdated.
Modern analysis systems go much deeper. They evaluate not only the number of actions but also session behavior, request structure, the network profile of the connection, and how consistent technical parameters are with each other. That is why the question of how websites distinguish a bot from a human is no longer about a single signal but about an entire system of signals working together.
If you work with automation, APIs, or data scraping, understanding these mechanisms is not theoretical knowledge – it becomes part of your technical architecture.
Behavioral Signals: More Than Click Speed
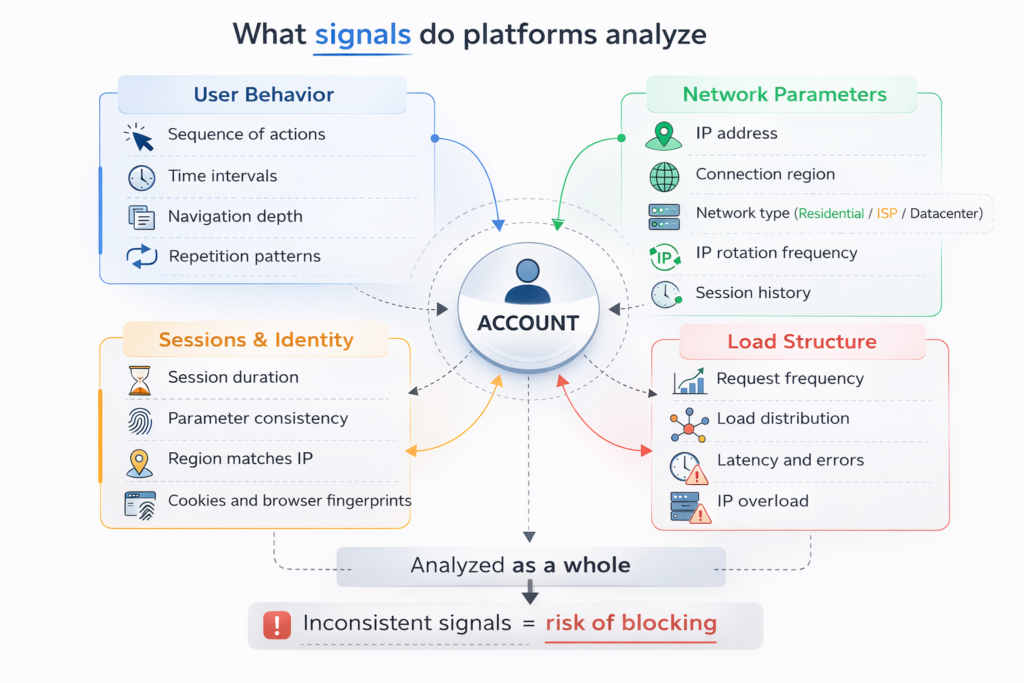
The first layer of analysis focuses on behavioral signals. The system evaluates how a session behaves:
- sequence of actions
- depth of browsing
- pauses between operations
- repetition of patterns
A real user behaves unevenly. They read, pause, scroll back, and interact with different page elements in an irregular way. A bot, on the other hand, often follows a strict logic – identical intervals, identical sequences, identical request structures. Even at low activity levels, a predictable pattern can be recognized as automated behavior. The issue is rarely speed itself. The issue is repetition.
Network Profile of the Request
The second layer is the network profile. Every visit carries technical parameters along with the action itself:
- IP address
- connection region
- network type
- frequency of IP changes
- history of previous connections
If an IP address changes too frequently without a clear session logic, or if the account region does not match the connection region, the system detects inconsistency. IP rotation itself is not the problem – its alignment with the scenario is what matters. For example, during long sessions, frequent IP switching may look suspicious. In high-volume scenarios, not rotating at all may overload a single IP. That is why factors such as proxy stability and rotation logic directly influence how an account is perceived by the platform.
Infrastructure Level: Where the Real Difference Appears
When working with APIs, the picture becomes even more transparent for the platform. API integrations allow systems to analyze the structure and frequency of requests more precisely. If load distribution is uneven, latency spikes appear, and certain IPs become overloaded, this becomes visible much faster than during manual interaction.
In data scraping scenarios, the effect intensifies. Thousands of similar requests create a stable pattern. Even minor technical instability, when combined with traffic scaling, starts repeating and becomes part of the profile.
This is where the differences between residential, ISP, and datacenter proxies begin to matter. They differ not only by IP type, but also by how they behave under load, how intensively they are used, and how stable they remain during long sessions.
Why Some Accounts Last Longer Than Others
When everything is combined, it becomes clear that platforms evaluate not a single action, but the coherence of the entire environment.
They analyze:
- whether behavioral signals are consistent
- whether region and IP align
- how IP rotation is structured
- whether load is distributed evenly
If these elements are misaligned, even careful activity can appear abnormal. In professional practice, what matters is not simply the formal classification of proxies, but how they behave within a real infrastructure. For example, MangoProxy is used as part of network architecture in automation, API workflows, and traffic scaling scenarios. What matters most is not the declared proxy type, but how it performs over time and under load.
Practical Conclusions
For stable operation without unnecessary restrictions, it is important to think at the architecture level. Websites analyze a combination of signals, so proxy type must match the usage scenario, IP rotation should be logically configured, the IP pool must provide sufficient capacity, and network and behavioral parameters must remain interconnected. Anti-fraud systems respond not only to activity levels, but also to internal inconsistencies between these factors.
FAQ
Can websites really detect that I use automation?
Yes, especially if automation creates atypical load patterns or an unstable connection profile. Platforms analyze request rhythm, session behavior, and network parameters together.
Is lowering action speed enough to avoid restrictions?
Not always. Even at low activity levels, session consistency, IP rotation logic, and region alignment remain important.
Why does one account remain stable while another does not, even with similar actions?
The difference often lies in infrastructure. Proxy type, IP pool size, and load distribution over time can significantly affect stability.
Is it possible to eliminate restriction risks entirely?
No. Platform algorithms are constantly evolving. However, technical risks can be reduced if the connection environment is structured logically and remains stable over time.
Conclusion
The question of how websites distinguish a real user from a bot is no longer about click speed. Today, platforms evaluate behavior, connection parameters, and traffic structure as parts of a unified system.
If the infrastructure is built logically, load is distributed evenly, and proxies match the task, technical signals remain consistent. And it is this consistency that most often determines long-term stability when working with automation, APIs, and traffic scaling.