Using Proxies for Web Scraping: Infrastructure, Rotation and Best Practices

Web scraping is a common method for collecting publicly available data from websites at scale. However, platforms often monitor traffic patterns and apply rate limits or access restrictions when automated activity is detected.
Proxy infrastructure helps distribute scraping requests across multiple IP addresses, making large-scale data collection more reliable and operationally sustainable.
This guide explains how proxies are used in scraping workflows, how rotation improves performance and which proxy types are best suited for different data collection strategies.
Key Takeaways
- proxies help distribute scraping requests across multiple identities
- rotating proxy pools improve access continuity
- different proxy types provide different detection resistance
- session control is important for structured scraping
- hybrid proxy strategies improve scalability
Why Proxies Are Essential for Web Scraping
When scraping without proxies, all requests originate from a single IP address. This can quickly trigger platform defenses such as:
- rate limiting
- CAPTCHA challenges
- temporary blocks
- traffic filtering
Using proxy routing helps simulate distributed user behavior and reduces request concentration signals.
Teams often combine rotation strategies explained in IP Rotation Explained Guide to scale scraping environments safely.
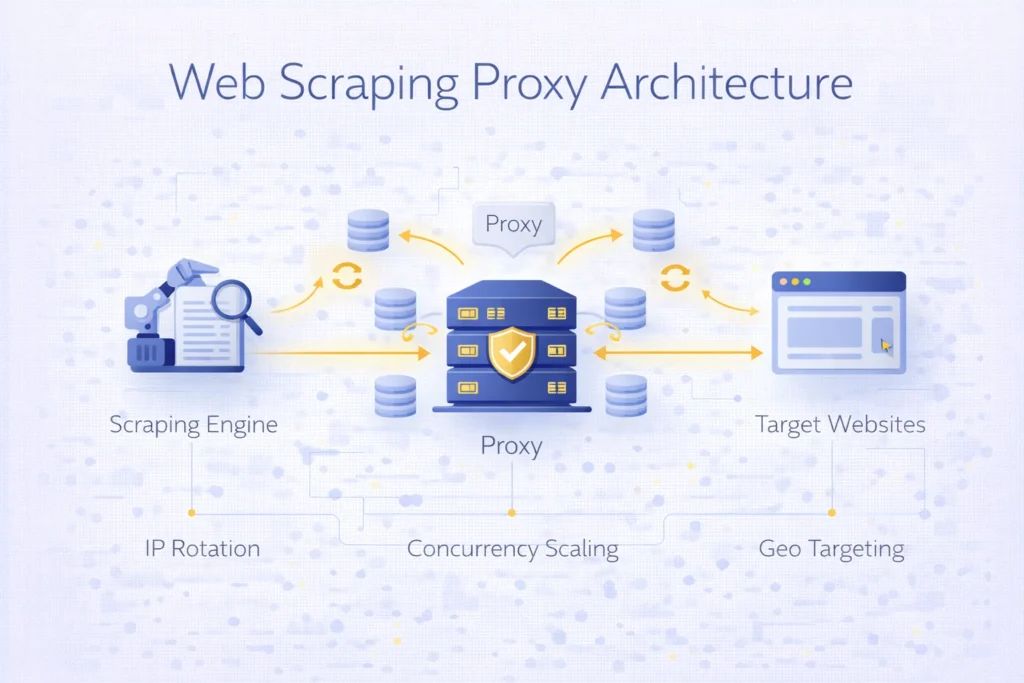
How Proxies Work in Scraping Architectures
A typical scraping infrastructure includes:
- scraping engine or automation framework
- proxy gateway managing IP pools
- target websites or APIs
- data storage pipelines
Each request is routed through a proxy endpoint, which becomes the visible identity for the destination platform.
Proxy gateways may rotate IP addresses automatically or maintain sticky sessions depending on workflow requirements.
Choosing the Right Proxy Type for Scraping
Different proxy infrastructures provide different operational advantages.
Residential Proxies
Residential proxies use IP addresses assigned to real household devices. This makes scraping traffic appear more like normal user activity.
They are often used for:
- SERP data collection
- price monitoring
- marketplace scraping
- geo-targeted content testing
👉 Learn more in Residential Proxies Guide.
Datacenter Proxies
Datacenter proxies provide high-speed connectivity and are suitable for large-scale scraping operations where concurrency is required.
They are often used for:
- bulk extraction
- structured crawling
- API scraping
- large dataset generation
👉 See comparison in Static vs Rotating Datacenter Proxies.
ISP Proxies
ISP proxies combine datacenter performance with residential IP identity. They are commonly used for workflows requiring stable sessions.
👉 Read full explanation in ISP Proxies Guide.
Mobile Proxies
Mobile proxies offer dynamic carrier IP routing and are sometimes used for sensitive scraping scenarios.
👉 Explore details in Mobile Proxies Guide.
Static vs Rotating Proxies in Scraping
Rotation is one of the most important elements of scraping success.
- static proxies support login persistence
- rotating proxies support distributed discovery
Understanding routing differences in Static vs Rotating Proxies Guide helps design effective scraping pipelines.
Best Practices for Scraping with Proxies
Use Realistic Request Patterns
Avoid sending thousands of requests simultaneously from the same identity.
Combine Rotation with Delays
Traffic pacing improves access continuity.
Match Proxy Type to Task
Residential proxies may be better for discovery, while datacenter proxies support bulk processing.
Monitor Block Signals
Adaptive rotation can respond to platform defenses.
Common Scraping Challenges
- IP bans
- CAPTCHA triggers
- content throttling
- geo restrictions
- inconsistent session behavior
Proper proxy routing helps mitigate these issues but must be combined with structured execution logic.
Web Scraping Infrastructure at MangoProxy
MangoProxy provides scalable proxy networks designed for data collection workflows.
These include:
- rotating residential proxy pools
- high-performance datacenter clusters
- static ISP routing environments
- mobile proxy rotation
Organizations can combine these layers to build resilient scraping architectures.
Glossary
Scraping Engine – automation system collecting data
Rate Limit – platform request restriction
Proxy Pool – collection of IP endpoints
Session Persistence – maintaining consistent identity

Frequently asked questions
Here we answered the most frequently asked questions.
Why are proxies needed for web scraping?
They help distribute requests and reduce detection risk.
Which proxy is best for scraping?
Residential proxies are often preferred for discovery, while datacenter proxies support high concurrency.
Do rotating proxies guarantee success?
No. Rotation improves reliability but scraping strategy also matters.
Can scraping be done without proxies?
Yes, but scaling becomes difficult due to rate limits and blocks. more stable routing setups and reduce detection risks.