Rotating vs Static Proxy for Web Scraping
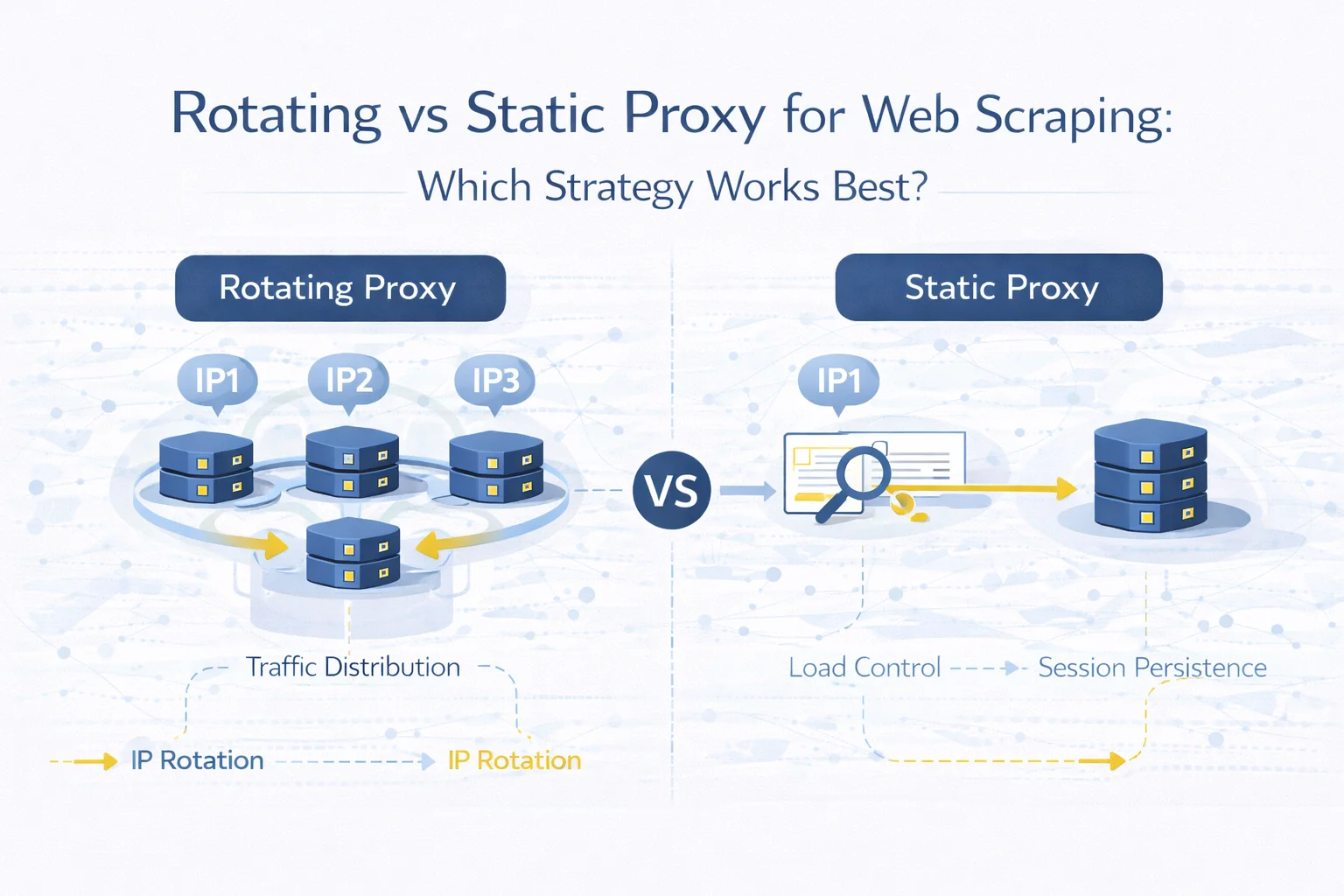
Choosing the right proxy rotation strategy is one of the most important architectural decisions in web scraping.
While some scraping workflows require continuous IP rotation to distribute requests, others rely on persistent connections that maintain a stable identity during the entire session.
Understanding when to use rotating proxies and when static routing is more effective helps scraping teams improve data collection reliability while controlling infrastructure costs.
Key Takeaways
- rotating proxies distribute requests across multiple IP identities
- static proxies maintain a consistent session identity
- discovery scraping benefits from rotation
- authenticated workflows require stable sessions
- hybrid scraping architectures often combine both models
Static vs Rotating Proxy Overview
| Proxy Strategy | Identity Behavior | Best Use Case | Detection Risk | Cost Efficiency |
| Rotating proxies | IP changes frequently | discovery scraping | lower | medium |
| Static proxies | IP remains constant | session scraping | medium | high |
👉 See full infrastructure explanation in Static vs Rotating Proxies (Ultimate Guide)
How Rotating Proxies Work in Scraping
Rotating proxies dynamically change the IP address used for outgoing requests.
Rotation may occur:
- per request
- per session
- at fixed time intervals
- after detection signals
This strategy spreads traffic across multiple identities, making scraping behavior appear more distributed.
👉 Explore rotation logic in IP Rotation Explained
Advantages of Rotating Proxies
Better Request Distribution
Scraping thousands of pages from the same IP can trigger rate limits. Rotation reduces traffic concentration.
Higher Discovery Success
When collecting new URLs or exploring large websites, rotating proxies help maintain access continuity.
Reduced Block Risk
Platforms analyzing traffic patterns are less likely to detect distributed request activity.
Limitations of Rotating Proxies
Despite their advantages, rotating proxies are not ideal for every scraping task.
Common challenges include:
- broken login sessions
- inconsistent cookies
- cart or account state loss
- difficulty maintaining persistent browsing flows
These issues often appear when scraping requires authenticated access.
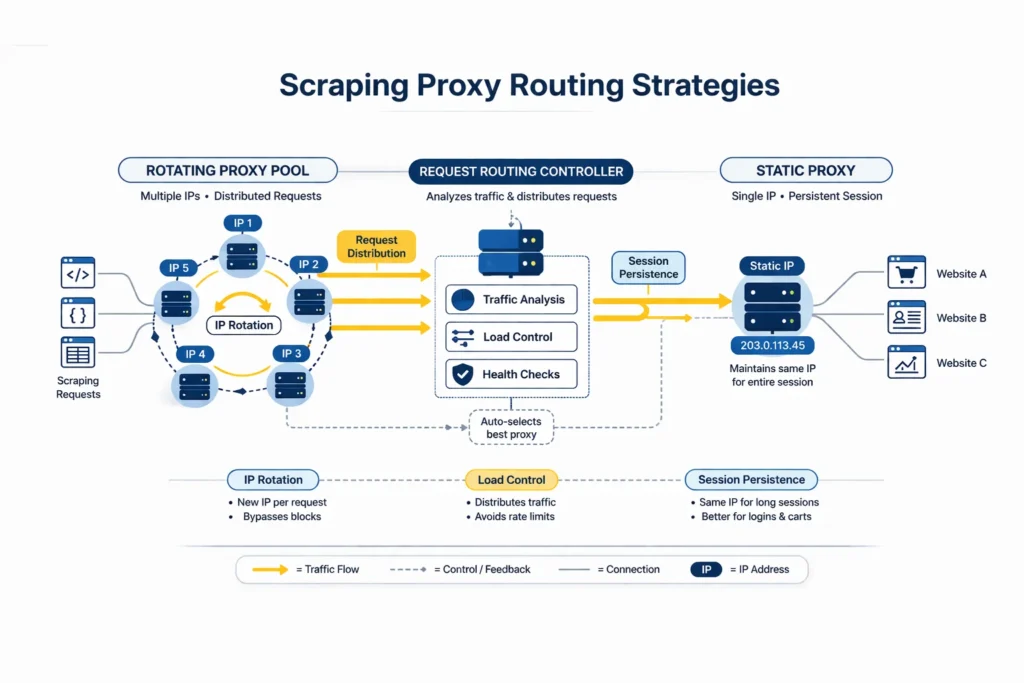
How Static Proxies Work in Scraping
Static proxies maintain a fixed IP address for the duration of the connection.
Instead of constantly changing identity, the scraper appears to operate from a consistent location.
Static routing is particularly useful when scraping workflows involve:
- login authentication
- session persistence
- shopping cart monitoring
- marketplace automation
👉 Learn session architecture in ISP Proxies Guide
Advantages of Static Proxies
Session Stability
Persistent identity prevents session resets during long scraping operations.
Reliable Login Workflows
Platforms often expect login activity to come from a consistent location.
Easier Debugging
Static routing makes troubleshooting scraping errors simpler.
Limitations of Static Proxies
Static proxies may encounter higher detection risk if request volume becomes excessive.
Common issues include:
- rate limits
- IP reputation degradation
- platform throttling
These risks increase when scraping large datasets without traffic pacing.
Hybrid Scraping Strategy
Most advanced scraping infrastructures combine rotating and static proxies.
Example architecture:
| Scraping Stage | Proxy Strategy |
| Discovery crawling | rotating residential proxies |
| Bulk data extraction | datacenter proxy pools |
| Authenticated sessions | ISP static proxies |
| Sensitive interactions | mobile proxies |
👉 Explore layered execution models in Best Proxy for Web Scraping
Choosing the Right Strategy
Selecting between rotating and static proxies depends on scraping requirements.
Use Rotating Proxies If
- collecting large datasets
- exploring unknown pages
- scraping search engines
- distributing requests across regions
Use Static Proxies If
- scraping logged-in dashboards
- maintaining cookies and sessions
- performing structured monitoring tasks
Cost Considerations
Scraping teams often underestimate the impact of retry rates on proxy costs.
A cheaper proxy pool with high block frequency may produce higher effective costs than a more reliable network.
Balancing rotation strategies with session persistence often leads to better long-term efficiency.
Scraping Diagnostics
Before launching scraping workflows, engineers should validate routing identity.
Key checks include:
- confirming visible IP
- verifying ASN classification
- testing geographic routing
Tools like:
can help confirm proxy configuration.
Final Thoughts
Rotating proxies and static proxies serve different roles in scraping infrastructure.
Successful scraping systems rarely rely on only one routing strategy. Instead, they combine dynamic discovery layers with stable session routing to achieve scalable and reliable data extraction.

Frequently asked questions
Here we answered the most frequently asked questions.
Are rotating proxies better for scraping?
They are generally better for large-scale discovery scraping where request distribution matters.
When should static proxies be used?
Static proxies are useful when scraping requires login sessions or persistent identity.
Can rotating proxies maintain sessions?
Some providers offer sticky sessions, but persistent identity is usually more reliable with static proxies.
Do scraping systems use both proxy types?
Yes. Hybrid routing architectures are common in modern scraping pipelines.rkload characteristics achieve more predictable scaling outcomes.